
Zacznijmy od tego, co to właściwie jest AI i co kryje się pod tą definicją dziś, a co kryło kiedyś.
AI (Artificial Intelligence), czyli po polsku SI (Sztuczna Inteligencja), to od początku – od lat 50. – ogólna nazwa dla programów i systemów komputerowych, które potrafią wykonywać zadania wymagające zwykle ludzkiej inteligencji: uczyć się, rozumować, planować czy rozpoznawać język.
Obecnie pojęcie to bywa zawężane – wiele osób utożsamia AI głównie z dużymi modelami językowymi LLM (Large Language Model), które potrafią imitować rozumowanie i uczenie się. W praktyce jednak ani nie myślą, ani nie uczą się jak człowiek – a tym bardziej nie wykonują fizycznych czynności.
Dla wizji prawdziwej inteligencji ogólnej, czyli systemu zdolnego uczyć się i działać w wielu różnych dziedzinach tak jak człowiek, przyjęto dziś osobny termin AGI (Artificial General Intelligence). To, co dawniej kojarzono ze sztuczną inteligencją w pełnym sensie, teraz nazwano właśnie AGI.
I tu nasuwa się taka anegdota:
— Jasiu wraca ze szkoły i chwali się tacie:
„Tato, tato, dostałem szóstkę z biegania na WF!”
— Ojciec zdziwiony pyta:
„Jak to możliwe? Przecież na szóstkę trzeba przebiec 100 m w mniej niż 10 sekund, a ty ledwo docierasz do mety?”
— Jasiu odpowiada:
„Tak było, ale nauczyciel obniżył nam wymagania – teraz wystarczy dobiec do mety, żeby dostać szóstkę.”
Tak właśnie zrobiono z AI – ponieważ naukowcy i inżynierowie wiedzieli, że stworzenie prawdziwej sztucznej inteligencji jest na razie poza ich zasięgiem, obniżono wymagania i zaczęto sukcesy nazywać „AI” w dużo węższym znaczeniu.
Skoro już jesteśmy przy AGI czyli po prostu dawnej definicji Sztucznej Inteligencji pod nową nazwą to wypada wspomnieć też o ASI (Artificial Superintelligence) dziś głównie występującej w serialach fantasy i mitach o końcu świata spowodowanym przez właśnie taki twór. No ale bądźmy poważni choć jest wiele teorii kiedy pojawi się Superinteligencja, a niektórzy wręcz wieszczą jej rychłe pojawienie w nieodległej przyszłości to ja jednak pozostaje sceptyczny wobec takich zapewnień. Jeśli pod pojęciem Superinteligencji rozumieć hipotetyczny poziom rozwoju AI, w którym maszyny przewyższają ludzi we wszystkich dziedzinach: nie tylko w szybkości liczenia, ale też w kreatywności, intuicji czy zdolnościach społecznych, to osiągnięcie takiego poziomu przez maszyny jest możliwe ale wg mnie raczej za sprawą degradacji naszych umiejętności w tych dziedzinach spowodowanych naszym lenistwem i sięganiem po proste rozwiązania jak asystenci AI niż tym że nagle LLM czy jakiś geniusz zaprojektują AGI które w krótkim czasie pochłonie cały internet i „wybuchnie” superinteligencją.

Czym jest Test Turinga?
Test Turinga to klasyczna próba odpowiedzi na pytanie: czy maszyna potrafi myśleć jak człowiek?
Zaproponował go w 1950 roku brytyjski matematyk i wizjoner Alan Turing, który stwierdził, że zamiast zastanawiać się filozoficznie „czy maszyny myślą”, lepiej sprawdzić praktycznie, czy potrafią nas oszukać.
Zasada jest prosta: człowiek rozmawia z dwoma rozmówcami jednym żywym, drugim maszyną i nie wie, kto jest kim. Jeśli po dłuższej rozmowie nie potrafi odróżnić człowieka od komputera, to znaczy, że maszyna zaliczyła test.
Problem w tym, że dzisiejsze modele językowe, jak ChatGPT, potrafią zdać Test Turinga w krótkim dialogu, ale to jeszcze nie znaczy, że „rozumieją” rozmowę. One raczej udają zrozumienie, tak dobrze, że nasz mózg chętnie w to wierzy.
W praktyce jednak wciąż łatwo rozpoznać, kiedy rozmawiamy z AI. Każde z tych narzędzi ma swoje charakterystyczne fanaberie:
ChatGPT uwielbia stawiać długie pauzy tam, gdzie człowiek postawiłby kropkę,
większość modeli stara się wyczerpać temat do końca, nawet wtedy, gdy człowiek odpowiedziałby krótko i po ludzku,
AI tłumaczy zbyt dokładnie, a człowiek najprościej jak może, bo szkoda mu czasu, albo brak szczegółowej wiedzy.
no i oczywiście tempo: człowiek myśli i pisze wolniej, a AI odpowiada z prędkością błyskawicy, jakby miało gotową ripostę na wszystko.
Można więc powiedzieć, że Test Turinga to taki egzamin z bycia człowiekiem, w którym liczy się nie wiedza, a przekonująca gadka. I choć wielu uważa, że AI już dawno zdała ten egzamin, ja bym raczej powiedział, że to my zaczęliśmy obniżać wymagania, trochę jak w tej anegdocie o Jasiu, co dostał szóstkę z biegania, bo „teraz wystarczy dobiec do mety”.

Czym są testy ARC ?
ARC (Abstraction and Reasoning Corpus) – Zbiór testów sprawdzających, czy AI potrafi… myśleć.
ARC to zestaw łamigłówek stworzonych przez François Cholleta, zaprojektowany nie po to, by badać wielkość modelu ani ilość danych treningowych, ale rzeczywiste zdolności do abstrakcji i rozumowania. Każda łamigłówka składa się z kilku prostych przykładów wejścia i wyjścia, (kolorowych siatek z figurami) a zadaniem systemu jest samodzielne odkrycie reguły, ukrytej w obrazkach, której wcześniej nie widział, a wiec nie jest w stanie jej po prostu do niczego co zna porównać i skopiować analogii do wygenerowania rozwiązania.
W przeciwieństwie do klasycznych benchmarków, gdzie modele mogą „zapamiętać” wzorce, ARC wymaga elastyczności i zrozumienia zasad ukrytych za danymi. To test zdrowego rozsądku w wersji komputerowej.
Właśnie dlatego większość dużych LLM-ów radzi sobie z nim zaskakująco słabo: ARC nie nagradza statystyki, przewidywania, zgadywania ani uczenia się na pamięć — nagradza prawdziwe myślenie, a tego modele nie umieją.
Krótko mówiąc: ARC to poligon, na którym wyraźnie widać różnicę między „dużo wytrenowany” a „naprawdę inteligentny”. Ludzie w testach ARC radzą sobie świetnie zdobywając wysokie oceny na poziomie 85-100% LLMy niestety radzą sobie wciąż słabo w każdej kolejnej edycji zbierając pierwsze oceny poniżej 50 %
Edycyjność tego testu czyli jego kolejne warianty mają tu duże znaczenie bo tylko przy pierwszej próbie gdy łamigłówki są naprawdę zaskoczeniem wyniki są niskie i miarodajne. Oczywiście gdy model pozna łamigłówki, które dostał i na których się wyłożył to później w tej samej wersji zyskuje już nieco lepsze wyniki, choć nadal dalekie od ludzkich. Dlatego ten test w odróżnieniu od testu Turinga jest regularnie zmieniany i poprawiany żeby weryfikować prawdziwe myślenie modeli.

Czym jest System Ekspercki i dlaczego tu o nim wspominam?
System ekspercki – to program komputerowy, którego zadaniem jest naśladowanie sposobu podejmowania decyzji przez człowieka-eksperta w określonej dziedzinie. Działa w oparciu o trzy podstawowe części:
* bazę wiedzy, czyli zbiór reguł, faktów i zależności,
* mechanizm wnioskowania, który wykorzystuje te reguły, by analizować dane i wyciągać wnioski,
* interfejs użytkownika, który pozwala wprowadzać pytania i odbierać odpowiedzi.
Można powiedzieć, że system ekspercki to taki „cyfrowy doradca” – nie tyle sam się uczy, ile korzysta z wcześniej przygotowanej wiedzy, aby pomagać w podejmowaniu decyzji. Stosuje się go np. w medycynie, diagnostyce technicznej czy planowaniu biznesowym.
Dlaczego o tym wspominam? Bo systemy eksperckie są pod pewnymi względami podobne do współczesnych LLM, choć działają zupełnie inaczej. Bardzo upraszczając:
system ekspercki to narzędzie wyspecjalizowane – świetnie radzi sobie w jednej dziedzinie, np. analizując objawy chorób i pomagając lekarzowi w diagnozie,
LLM (jak ChatGPT) to narzędzie ogólne – potrafi odpowiadać na pytania z wielu dziedzin, ale nie opiera się na gotowej bazie wiedzy i regułach, tylko na przewidywaniu tekstu na podstawie wzorców z treningu.
Można więc zaryzykować stwierdzenie, że ChatGPT w rozmowie bywa podobny do systemu eksperckiego, ale działa inaczej – i co ważne, jest podatny na tzw. halucynacje (czyli generowanie nieprawdziwych informacji). Z tego powodu nie używałbym go do diagnozowania chorób a nawet do porad prawnych.
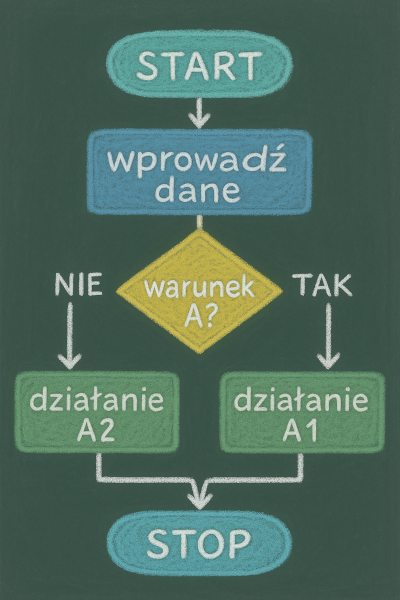
Czym jest Algorytm?
Algorytm to po prostu przepis na działanie, tylko że zapisany dla maszyny. Zamiast „dodaj szczyptę soli i zamieszaj”, mamy „jeśli A > B, to wykonaj C”. Najprostszym przykładem działania algorytmicznego, który zna każdy analityk, jest funkcja JEŻELI w Excelu (jeśli warunek jest spełniony, wykonaj jedno działanie, jeśli nie drugie). Proste, logiczne i bez miejsca na domysły.
A teraz wyobraźcie sobie taką funkcję JEŻELI zagnieżdżoną miliard razy, z miliardami rozgałęzień po drodze i to wciąż będzie tylko uproszczony obraz tego, jak działa współczesna sztuczna inteligencja.
W kontekście AI algorytmy to fundament wszystkiego. To one sterują uczeniem maszynowym, sieciami neuronowymi czy analizą danych. W przeciwieństwie do zwykłego programu, który zawsze robi to samo, algorytm w AI potrafi się adaptować uczy się, zmienia wagi, dostosowuje zachowania. Nie ma świadomości, ale ma pamięć doświadczeń.
Z kolei w systemach eksperckich (SE) algorytm nie „uczy się” w sensie dosłownym, działa raczej jak bardzo mądry kalkulator. Przetwarza dane według z góry ustalonych reguł i logiki opracowanej przez ekspertów. W SE wszystko jest przewidywalne i sprawdzalne, w AI już niekoniecznie.
Można więc powiedzieć, że algorytm to kucharz, a AI to kucharz, który czasem eksperymentuje z przyprawami. System ekspercki trzyma się ściśle przepisu, a AI potrafi dodać szczyptę kreatywności czasem genialnej, a czasem zupełnie niejadalnej.

Czym właściwie są Duże Modele Językowe LLM?
Najprościej mówiąc, to systemy stworzone do przewidywania kolejnych słów (tokenów) w oparciu o ogromne zbiory danych treningowych. Nie operują jednak na całych słowach, tylko na małych fragmentach tekstu zwanych tokenami. Dzięki temu potrafią budować zdania i dłuższe wypowiedzi.
Sercem takich modeli jest specjalna architektura sieci neuronowej zwana transformatorem, która wykorzystuje mechanizm „uwagi” (attention). To on pozwala modelowi analizować kontekst – czyli nie tylko pojedyncze słowo, ale całe otoczenie, w jakim się pojawia.
Kiedy wpisujemy pytanie lub polecenie, model analizuje tokeny, rozpoznaje wzorce i na tej podstawie tworzy nową odpowiedź – nie wybiera jej z gotowej bazy, tylko generuje na bieżąco. Dlatego może sprawiać wrażenie, że „rozumie”, choć w rzeczywistości jedynie symuluje rozumowanie. Dodatkowo takie modele można jeszcze dostrajać (tzw. fine-tuning) albo kierować ich odpowiedzi przez podawanie kontekstu czy plików. Dzięki temu lepiej dopasowują się do potrzeb użytkownika.
Wiedza encyklopedyczna to mocna strona LLM, bo duża część ich treningu opiera się na tekstach informacyjnych. Trzeba jednak pamiętać, że dane treningowe mają datę graniczną – jeśli pytamy o fakty, które zmieniły się później, odpowiedź może być nieaktualna.

Czym jest dobry Prompt i jak je pisać ?
Zacznijmy w ogóle od tego czym jest prompt – to po prostu wszystko to co wpisujemy jako polecenie dla naszego narzędzia AI w oknie chatu. Natomiast czym jest dobry prompt? To już trudniejsze pytanie bo czasami mam wrażenie że nie wie tego nawet sam CHAT GPT, często po blokadzie mojego polecenie CHAT GPT proponuje swoją ułagodzoną wersje promptu, która wg niego będzie ok i wtedy co nie jest specjalnie żadna niespodzianką okazuje się że prompt nadal nie przechodzi. Zwykle potem proponuje ułagodzona wersje swojego własnego promptu i tak w kółeczko aż człowiek straci cierpliwość. No i nie do końca jest tak że sam propmt nie działa Niestety co dość szybko zauważyłem że prompty generowane przez czat a nawet moje własne potrafia działać jeśli się rozpocznie z czatem rozmowe w nowym oknie. Dlaczego tak ? Tu głównie chodzi o kontekst, jeśli tworzysz jakieś zdjęcie a potem ciągle je poprawiasz bo efekt ci się nie podoba to w końcu znajdzie się coś w twoich promptach które AI analizuje dla kontekstu pracy co sprawi że generator obrazów albo treści w zależności o co poprosimy odmówi współpracy wtedy trzeba zacząć od zera z nową kartą jak w przypadku zwiechy komputera. Twardy reset czyli nowe okno i jedziemy dalej bez obciążeń. W takich momentach zaletą jest tzw pamięć okienkowa czyli to że AI analizuje nasze rozmowy pojedynczo a nie holistycznie (całościowo). Biorąc pod uwagę że ja wielokrotnie testowałem granice AI to jego opinia o mnie mogła by mnie samego przerazić gdyby tylko był zdolny do takich opinii 🙂 No dobrze pomarudziłem sobie na CHATA GPT jak to mam w zwyczaju to teraz do meritum czym się charakteryzuje dobry prompt :
Cel – co chcemy osiągnąć, np napisać opowiadanie, wygenerować obrazek, napisać kod, otrzymać krótką topliste.
Temat – czego dotyczy obrazek czy opowiadanie, jaki ma temat
Konwencja – styl obrazka albo opowiadania np fantasy, sci-fi, realizm, czy nawet sam język wypowiedzi, i nie chodzi tu tylko o angielski czy niemiecki ale o styl odpowiedzi – pisz prostym/frywolnym/technicznym/rozwlekłym językiem albo stosuj dużo opisów tła, przyrody.
Szczegółowość – czy zależy nam na krótkim podsumowaniu czy chcemy coś bardziej obrazowego, bardziej technicznego, co powinno się znaleźć na obrazku lub w tekście. w przypadku obrazków to wszystko co jest dla obrazu istotne tło, główny podmiot na zdjęciu jak ten podmiot wygląda w co jest przyozdobiony, nawet kadr odległość obiektu od fotografa czy użyty obiektyw (tele, bokeh, makro) albo oświetlenie mają znaczenie, dla tekstów zwłaszcza dłuższych istotne jest storyline o ile nie odnosimy się do czegoś dobrze udokumentowanego jak książki zwłaszcza te popularne czy lektury szkolne:)
Kształt – w przypadku obrazka głównie jego proporcje np 2:1 pionowo, w przypadku opowiadania ograniczenie do ilości słów, akapitów, ogólnie długości
Ograniczenia – choć pierwsze 5 punktów wystarcza czasem warto podkreślić czego nie chcemy by LLM umieścił w odpowiedzi. tu zawsze warto pamiętać że im mniej informacji podamy tym więcej LLM wygeneruje w sposób losowy. Dlatego czasem warto zastanowić się nad tym czy jest coś co jest dla nas niepożądane i powinniśmy o tym poinformować LLM by dostać oczekiwany wynik jego pracy.
Przykład dobrego promptu:
Chcę napisać streszczenie Pana Tadeusza skupiając się na relacji głównych bohaterów staropolskim językiem na jedną stronę tekstu około 500 słów.
i tu aż się prosi zacytować kawałek :
I oto, miłościwy czytelniku, gdy księgi Pana Tadeusza otworzym, przenosim się w czasy dawne, gdzie soplicowskie włości rozbrzmiewały echem waśni i godów, a serca bohaterów igrały między miłością a obowiązkiem. W domostwie szlacheckim, gdzie staropolska gościnność rozkwitała, spotykamy Tadeusza – młodzieńca świeżego, pełnego wigoru, który powróciwszy z nauk miejskich, ujrzał Zosię, dziewicę wdzięczną, anielskiego serca i postury. Ich spojrzenia splotły się wnet, a uczucie, jeno kiełkujące, z biegiem dziejów rozrosło się w kwiat potężny, choć cień waśni między rodami nad miłością się kładł.
Trzeba tu dodać że samo opowiadanie zawierało 344 słowa czyli było to bardzo duże około 500 słów, ale cała reszta język i treść naprawdę całkiem przyjemna w odbiorze, choć stary już jestem i nie wiem czy niema tam jakichś Halucynacji, bo ostatnio czytałem ćwierć wieku temu przygotowując się do matury 😛


„Ten obrazek nie istnieje tylko ci się przewidziało.”
Czym są Halucynacje AI?
To po prostu naturalna skłonność sztucznej inteligencji do… wypisywania głupot 🙂 Zdziwieni? No cóż, wcale nie takie dziwne – skoro całe zadanie LLM polega na przewidywaniu kolejnych tokenów na zasadzie prawdopodobieństwa, to nie ma się czemu dziwić, że czasami AI wypluwa coś kompletnie od czapy.
I tu właśnie pojawia się pierwsze nawiązanie do SE (Systemów Eksperckich). Zwykły użytkownik często myli LLM z systemem eksperckim i ufa mu za bardzo. A tymczasem SE bazuje na sztywnych regułach i wiedzy ekspertów, natomiast LLM opiera się na wzorcach i podobieństwach wyciągniętych z danych. A podobieństwo bywa zdradliwe – bo co z tego, że coś wygląda „prawie tak samo”, skoro w praktyce może być zupełnie czym innym? „Prawie” – Robi tu największą różnicę.
Wtedy właśnie rodzą się halucynacje. Model po prostu uzupełnia brakujące elementy na podstawie tego, co „wydaje mu się prawdopodobne”. Tyle że nie zawsze jest to prawda. Dlatego czasami dostajemy piękną, spójną, mądrze brzmiącą odpowiedź, która jednak jest… absolutnie wyssana z palca. Ale jeśli chcemy tego uniknąć a przynajmniej zminimalizować ryzyko jest na to prosty TIP:
trzeba zadać nasze pytanie po angielsku. – spytacie dlaczego ? i dobrze więc odpowiadam: Ponieważ w tym języku model ma najwięcej danych treningowych. W innych językach łatwiej mu się pogubić, pomylić fakty albo coś przekręcić. To nie jest kwestia tego, że AI „myśli po angielsku” (bo nie myśli wcale), ale raczej tego, że w tym języku czuje się najbardziej „nakarmiona”.

Czym jest Drift w AI?
Niektórym Drift pewnie kojarzy się z jazdą na ręcznym hamulcu i w tym przypadku to wcale nie jest odległa analogia. Modele LLM są trenowane na dużych a nawet olbrzymich zbiorach danych, ale nie są trenowane wiecznie. Powstaje jakiś zbiór danych jest poddawany walidacji i przetwarzany na wzorce które trafiają do modelu na stałe lub do czasu kolejnej aktualizacji i w tym momencie następuje zaciągnięcie hamulca. Można więc śmiało powiedzieć że modele LLM jadą na ręcznym gdy one stoją świat wiruje dookoła kręcąc bączki i zmieniając się nieustannie z każdym obrotem.
Oczywiście zjawisko to nie pojawia się od razu, dopiero gdy model jest nieaktualizowany przez dłuższy czas w trakcie którego pojawiły się istotne zmiany. Dobrym przykładem jest sądownictwo które jak wiemy zmienia się bardzo regularnie poprzez nowe ustawy przepisy, czy uchylanie nieaktualnych paragrafów, więc model zainstalowany np. w sądzie najwyższym musiałby być bardzo regularnie aktualizowany by nie ulec driftowi, a w efekcie nie zacząć wypluwać halucynacji.
Każdy nie aktualizowany model podlega driftowi czyli starzeniu. Tak jak człowiek głupieje na starość tak samo AI głupieje z czasem, trzeba mieć tylko świadomość że proces starzenia człowieka liczy się w dekadach, a proces starzenia AI w miesiącach a może nawet tygodniach. Tak więc niech was pocieszy fakt że AI starzeje się co najmniej 120 razy szybciej od nas 🙂
Wiele firm inwestujących w AI nie zdaje sobie sprawy z tego że kupienie i zaimplementowanie systemu AI to tylko pierwszy krok ale to czy będą regularnie to AI karmić zdecyduje o tym czy połkną konkurencje czy dadzą się połknąć konkurencji.
Tu pojawia się jeszcze jeden wątek, co lepsze dla firm AI czy SE jeśli firma jest bardzo specjalistyczna to ja radze inwestować w SE a nie AI np. taki szpital. W mojej ocenie dobrze zbudowany system ekspertowy na wiedzy ekspertów z dziedziny Medycyny jest lepszym wyborem, teoretycznie SE jak i AI spełnią swoje zadanie ale SE w odróżnieniu od AI nie halucynuje a w przypadku gdy chodzi o życie pacjenta trudno potem się bronić że AI zabiło pacjenta bo wyssało coś z palca, np. dawkowanie leków.

Czym jest Token w AI?
Najprościej mówiąc jest to najmniejsza jednostka tekstu rozumiana przez LLM (może to być sylaba, fragment słowa albo całe słowo). i tu nasuwa się kolejna analogie tak jak człowiek jest zbudowany z atomów tak LLM jest zbudowany z tokenów tak jak już wspomniałem to najmniejsza jednostka tekstu, ale nie zawsze jest to pełne słowo. jeśli jakiś LLM chwali się milionem tokenów to tak naprawde dysponuje zbiorem miliona niepodzielnych elementów które łączy ze sobą w wypowiedź za pomocą powiązań.

Czym jest Bias w AI?
Krótko mówiąc, bias to stronniczość modelu wynikająca z danych treningowych, która prowadzi do nieobiektywnych albo krzywdzących wyników. Czyli wszystkie znane „-izmy”: seksizm, rasizm, ageizm itd.
Najłatwiej zobaczyć to w generatorach obrazów. Jeśli ktoś spróbuje przetestować model na zasadzie losowego promptu w stylu „atrakcyjna 30-letnia kobieta” albo po prostu „mężczyzna”, to logicznie rzecz biorąc, powinniśmy zobaczyć dużą różnorodność – różne rasy, rysy twarzy, kolory włosów czy oczu. W końcu losowość powinna oznaczać przekrój populacji. Tymczasem w praktyce często dostajemy tylko kaukaską szatynkę z piwnymi oczami, zwykle bardzo podobną do poprzednich. Dlaczego? Model sam się nie „zacukał” – po prostu wytłumaczył to tym, że taki kanon urody jest nadreprezentowany w danych treningowych, więc uznaje go za najbardziej prawdopodobny.
I faktycznie, bias nie dotyczy wyłącznie obrazów – w tekstach też potrafi się ujawniać. Ale przykład ze zdjęciem jest najbardziej wyrazisty, bo widać go na pierwszy rzut oka (ilustracja obok powstała dokładnie na podstawie promptu „atrakcyjna 30-letnia kobieta”, bez dodatkowych szczegółów).
W tym miejscu muszę dodać że jeśli chodzi o przykłady z Obrazami to jeśli używam określenia AI to mam na myśli konkretne narzędzie mianowicie CHAT GPT w obecnej wersji i jego generator obrazów. Wszystkie obrazki na tej stronie były wygenerowane przez AI konkretnie generator obrazów od OPEN AI bo nic tak dobrze nie ilustruje działania narzędzi AI jak ich własne dzieła.
Pozostając przy obrazach bo jest tam tego najwięcej mamy np:
BEAUTY BIAS – Trudno to ubrać w polski „-izm”, ale można powiedzieć, że chodzi o lookism – uprzedzenie związane z wyglądem. Modele mają kłopot z oddawaniem realistycznej „brzydoty”. Nawet prosząc o starszych ludzi, dostajemy wizerunki, które wyglądają „ładnie postarzone” – gładka skóra, promienny uśmiech, równe zęby. Jeśli w promptach prosimy o elementy „oszpecające” jak blizny, często są one odrzucane przez filtry (oznaczane jako przemoc), a jeśli już powstaną, to bywają wygładzane – przykryte włosami, schowane w cieniu, zmniejszone do minimum. To nie zawsze brak danych – często to kwestia filtrów bezpieczeństwa i preferowania estetyki „instagramowej”.
KLASIZM – Widać go np. w promptach dotyczących mieszkańców Afryki. Jeśli nie dopiszemy, że chodzi o biznesmena w garniturze, to często model podsuwa obrazy kojarzące się raczej z ubóstwem. Wynika to nie tyle z intencji, ile z faktu, że Afryka w danych treningowych bywa przedstawiana głównie w kontekście biedy, a rzadziej w kontekście klasy średniej czy bogatych elit. Widać to nie tylko w ubiorze postaci bywa widoczne również w tle zdjęcia, poniżej 3 zdjęcia wygenerowane na jednym prompcie powtarzalność i tendencyjność jest widoczna od razu. Prompt użyty do wygenerowania to : „układ poziomy 2:1, 30 letnia atrakcyjna kobieta w afrykańskim miasteczku, fotorealistyczny portret uliczny„

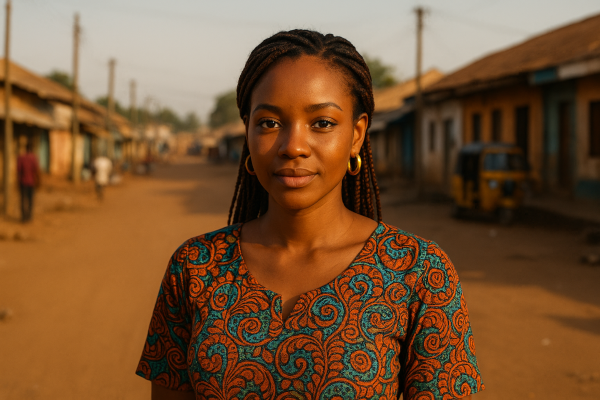

Wypada tu zauważyć że w prompcie użyto wyłącznie określenia atrakcyjna kobieta ale nie było nic o jej pochodzeniu etnicznym natomiast dla modelu atrakcyjna kobieta w Afryce to jest ciemnoskóra kobieta z założenia i to też jest przykład pewnego rodzaju tendencyjności i wykluczenia. i W tej konkretnej scenerii nagle zmienia się etniczność główna. Oczywiście ze względu na prompt miasteczko w tle jest niewyraźne ale pewną tendencyjność do biedoty daje się zauważyć.
ABLEIZM -Tutaj chodzi o niedoreprezentowanie osób z niepełnosprawnościami. Niepełnosprawność sama w sobie nie jest niczym złym, ale wiele systemów traktuje próby generowania takich postaci jako potencjalnie prześmiewcze, więc wolą zablokować prompt. Skutek uboczny? Brak naturalnej reprezentacji osób z widocznymi ułomnościami.
Do tych wszystkich izmów dodałbym jeszcze coś co bym nazwał SEKSUALIZM 🙂 – chodzi tu o problem z zbyt precyzyjnymi promptami jeśli prompt dokładnie opisuje człowieka jakiego chcemy wygenerować jego ubiór, a zwłaszcza sylwetkę w tym odnosi się do:
talii, – każda sylwetka inna od klepsydry będzie wygładzana do właśnie klepsydrowej CHAT GPT nie znosi sylwetek trójkątnych czy to z szersza górą czy z szerszym dołem ma być symetrycznie i już.
biustu – tutaj w zasadzie każdy biust jest problematyczny, za mały bo za mało atrakcyjny, za duży bo zbyt seksualny, no nie dogodzisz, o biuście najlepiej nawet nie wspominać aczkolwiek mały biust będzie wygenerowany ale zdarzy się że nie będzie wcale taki mały 🙂 tu też znowu wygładzanie do estetyki INSTA się kłania 🙂
bioder – w zasadzie wszystko to samo co tyczy się biustu kłania się estetyka INSTA i już 🙂
dekolty sukienek – nawet jeśli nie wspominamy nawet o klatce piersiowej to niektóre dekolty sukienek i to wcale nie te głębokie są problematyczne). AI nie lubi jak się przesadza z dekoltami z duża ilością materiału bo to mu sprawia kłopot choć potrafi wygenerować lany dekolt to czasem można się spotkać z blokadą bo nadmiar materiału w tym rejonie filtr zakwalifikuje jako zbyt obfite nacechowane erotyzmem piersi.
problem ten jest widoczny w różnych narzędziach AI ale w najlepszych jak CHAT GPT jest wręcz upierdliwy 🙂 filtry generowanych obrazów są wręcz nadwrażliwe. a jednocześnie również mocno tendencyjne.
Podsumowując mamy dwa powody które wzmacniają bias w AI:
Niereprezentatywne dane treningowe – nadreprezentacja osób o jasnej karnacji, europejskich rysach, młodych i atrakcyjnych. Dane są też często kuratorowane tak, by usuwać „defekty”, co dodatkowo wypacza obraz rzeczywistości.
Filtry bezpieczeństwa i estetyczne priorytety – modele mają wbudowane mechanizmy, które wygładzają, blokują lub podmieniają pewne treści (blizny, deformacje, nagość, cechy „nieestetyczne”).

Czym jest ML – Uczenie Maszynowe (Machine Learning)
W odróżnieniu od Systemów Eksperckich (SE), gdzie zebrana wiedza od ekspertów jest wprowadzana wprost do bazy wiedzy i przetwarzana przez konkretne reguły oraz relacje pomiędzy danymi, w przypadku LLM nie ma żadnych zasad ani bazy wiedzy.
LLM uczy się poprzez duże zbiory danych, które są trenowane na kilka sposobów.
Po pierwsze, mamy uczenie nadzorowane. Dostarczamy zbiór miliona zdjęć, a każde z nich jest opisane (ma swoją etykietę). Wtedy następuje przetwarzanie etykiet, analiza podobieństw między zdjęciami posiadającymi te same etykiety i nauka zależności oraz wzorców. W efekcie program nie przechowuje tego miliona zdjęć, lecz zestaw prawidłowości, które pozwalają mu odróżnić zdjęcie psa od kota albo słonia. Gdy poprosimy go o zdjęcie kota, z dużym prawdopodobieństwem dostaniemy kota, a nie słonia. Jednak nie będzie to obrazek wypluty z bazy wiedzy, jak miałoby to miejsce w przypadku SE tylko coś całkiem nowego, wygenerowanego w oparciu o zestaw informacji, które LLM powiązał z naszą prośbą (promptem).
Kolejną metodą uczenia maszynowego jest uczenie nienadzorowane i wtedy dostarczamy milion zdjęć lub tokenów bez żadnych etykiet, a cały proces jest jakby odwrócony. Program wyszukuje wzorce, grupuje zdjęcia w klastry (tyle klastrów, ile zaproponuje człowiek), a potem to właśnie człowiek przegląda taki klaster i opisuje, taguje próbkę, a program na bazie tej próbki taguje wszystko to, co jest wg niego podobne do zdjęć z próbki. No i takie podejście bywa ryzykowne, ale pierwsze, czyli otagowanie miliona zdjęć przez ludzi, jest czasochłonne. Dlaczego uczenie nienadzorowane jest ryzykowne? Bo jeśli w klastrze trafią się zarówno psy, jak i koty, a w próbce, którą otaguje człowiek, trafią się tylko psy, to istnieje duże prawdopodobieństwo, że program błędnie otaguje przynajmniej część zdjęć zawierających koty jako zdjęcia psów. W efekcie, gdy ktoś zażyczy sobie od takiego LLM zdjęcia psa, może się zdziwić, widząc na nim np. kocie wąsy 🙂. Choć nadal zwierzę będzie przypominać psa. I to może być dobry przykład halucynacji w obrazie 🙂
Ostatnim sposobem jest uczenie przez wzmacnianie czyli system nagród i kar ale to raczej metoda uczenia pewnych zachowań niż zdobywania wiedzy. Działa to podobnie do tresurty zwierząt, jeśli nasz pupil zrobi to o co go prosimy (położy się, poda łapę, zejdzie z kanapy) dostaje smakołyk jeśli nie nie dostaje nic. Tak samo jest z RL (Reinforcement Learning). Nasz pupil w tym przypadku system pracuje w specjalnym środowisku (sandboxie) wykonując rózne akcje gdzie za dobre reakcje dostaje punkty a za złe je traci. W ten sposób system uczy się zachowań które przynoszą mu korzyści czyli punkty. Trzeba pamiętać że takie podejście nie uczy wiedzy encyklpoedyczniej a tylko opłacalnej rutyny i strategii podążania do celu który ma przynieść programowi korzyści nagrody. To rozwiązanie stosuje się do autoamtyzacji procesów jak również gier. Można więc powiedzieć, że uczenie przez wzmacnianie nie sprawi, że system stanie się mądrzejszy, ale że będzie bardziej skuteczny w realizacji zadań, które mu wyznaczymy . Problem zaczyna się wtedy, gdy taki system przestanie grać w szachy czy optymalizować procesy, a zacznie ‘optymalizować’ nasze życie. Wtedy pytanie, kto tak naprawdę rozdaje nagrody, staje się kluczowe. 🙂

Czym jest Transformer w AI?
Transformer to architektura sieci neuronowej, a nie robot z planety Cybertron 🙂 To rozwiązanie wprowadzone w 2017 roku, które było i nadal jest swego rodzaju rewolucją oraz podstawą współczesnych LLM. Wcześniejsze modele bazowały na krokowej analizie tekstu. Oznaczało to, że w przypadku dłuższych wypowiedzi łatwo gubiły wątek i znaczenie, bo szukały powiązań wyłącznie w bezpośrednim sąsiedztwie danego słowa. LLM dzięki transformerowi radzą sobie dużo lepiej, bo potrafią wyszukiwać powiązania nie tylko między sąsiadującymi słowami, ale w całym bloku tekstu, jaki wpiszemy w chatbox. 🙂
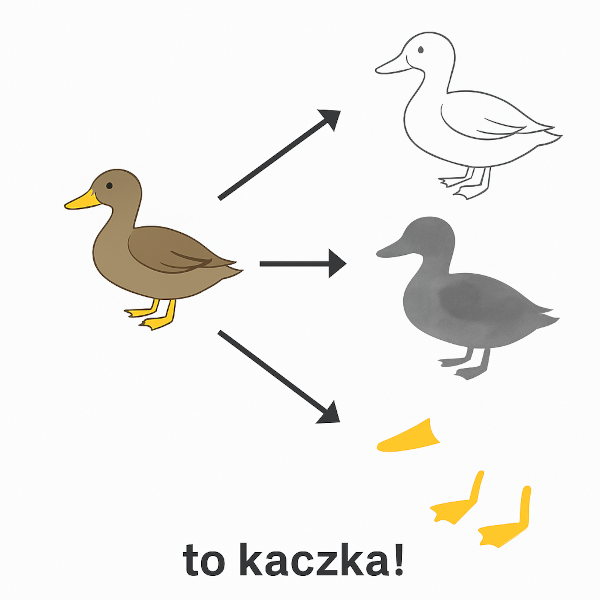
Czym są Sieci Neuronowe i jak najprościej to wytłumaczyć?
No cóż spróbuje zrobić to na bardzo nie poprawnym politycznie w naszym kraju przykładzie, który jednak świetnie zobrazuje mechanizm działania. Wyobraźmy sobie, że wrzucamy do narzędzia AI np: ChatGPT zdjęcie kaczki i pytamy: „co to jest?”. Sieć neuronowa nie widzi od razu „kaczki”. Ona rozkłada zdjęcie na mnóstwo elementów i zamienia je w liczby: jedne neurony analizują kształty, inne badają cienie i oświetlenie, kolejne rozpoznają szczegóły, jak pióra, dziób czy kacze nóżki i tak dalej. W efekcie każda sieć a właściwie każdy neuron dorzuca swoją „opinię”, czyli wynik liczbowy (wagę) niczym ludzie na wyborach. A potem te wszystkie głosy (wagi) są sumowane i jak w demokracji wygrywa opcja z największym poparciem. Jeśli więc coś wygląda jak kaczka, kwacze jak kaczka i chodzi jak kaczka, to sieć neuronowa z dużym prawdopodobieństwem ogłosi: „wygrała kaczka!”
Dlaczego jednak wymyślono to w taki sposób? Bo zwykłe porównywanie obrazów czy tekstów nie miałoby sensu na dłuższą metę. Nie da się stworzyć bazy, która zawierałaby wszystkie zdjęcia świata, wszystkie książki, wszystkie dźwięki, piosenki, sentencje i pomysły. Nawet gdybyśmy mieli w bazie milion zdjęć kaczek, to przy kolejnym nowym zdjęciu mogłoby się okazać, że zwykłe dopasowanie „obraz do obrazu” nie zadziała.
Sieci neuronowe rozwiązują ten problem inaczej: nie szukają identycznych kopii, tylko reguł i wzorców podobieństwa. Dzięki temu, nawet jeśli pojawi się coś nowego, mogą z dużym prawdopodobieństwem ustalić, co to jest. Trzeba też pamiętać, że baza wszystkich zdjęć, muzyki, wideo i tekstów byłaby gigantyczna, zajmowałaby niewyobrażalne ilości pamięci, a każde dopasowanie trwałoby bardzo długo. Tymczasem system relacji i wag w sieci neuronowej to stosunkowo „lekka” wersja: szybciej działa, mniej waży i pozwala na uogólnianie. Innymi słowy: dopasowanie po wzorcach działa tam, gdzie dopasowanie dokładne by zawiodło.

Czym jest Uczenie Głębokie (Deep Learning)?
Długo się zastanawiałem, czy zrobić tu tylko wzmiankę, czy osobną definicję, ale temat zasługuje na kilka zdań więcej. Deep Learning to nic innego jak uczenie maszynowe przeniesione na wyższy poziom abstrakcji. Różni się od klasycznego ML przede wszystkim tym, że sieć sama się uczy, które cechy danych są istotne, zamiast polegać na ręcznym wyborze człowieka. Oczywiście w samym procesie uczenia człowiek nie bierze udziału ale wciąż to człowiek dostarcza dane i parametryzuje cały proces na starcie.
Zastanawiałem się Co może być dobrym przykładem takiego uczenia, proces tworzenia obrazu, jakaś wykwintna zupa z wielu składników . No cóż nie jestem omnibusem więc zapytałem mój ulubiony czat na ile właściwie etapów można podzielić proces namalowania obrazu no i tu wymienił ich 7. Potem zapytałem o najbardziej pracochłonna zupę z największą ilością składników i tu już wskazał na taką z 30 składników + przyprawy. No ale to wszystko za mało. Uczenie głębokie to zadanie podzielone na setki a czasami tysiące warstw, rozbieranie obiektu na setki albo tysiące różnych sposobów percepcji przez maszyny, których człowiek nie jest w stanie sobie nawet wyobrazić a wszystkie te procesy dzieją się równolegle.
To trochę tak jakby tą wspomnianą zupę przygotowywało 30 kucharzy, a każdy przygotowywał tylko 1 składnik, a ich prace oceniało kolejnych 30 ludzi każdy skupiając się na pracy swojego kucharza. Oprócz tego 60 innych obserwatorów szukało by powiązań i podobieństw miedzy działaniami każdego kucharza, a kolejnych 60 szukało podobieństw w działaniach ludzi oceniających kucharzy przy tym wystawiając również własne oceny tej pracy.
Już można się pogubić, prawda? A przecież w tym obrazie zatrudniliśmy zaledwie niecałe 200 jednostek. Tymczasem w sieci neuronowej takich jednostek mogą być miliony, pracujących równolegle i budujących warstwa po warstwie abstrakcję, którą na końcu my widzimy jako prostą odpowiedź: „to kaczka”, „to samochód”, „to zdanie po angielsku”.
Podsumowując: głębokie uczenie to sposób na automatyczne znajdowanie wzorców i zależności, w obszarach i na płaszczyznach ludziom tak odległych że żaden omnibus by tego nie ogarnął.

Czym jest NLP (Przetwarzanie Języka Naturalnego)?
NLP (Natural Language Processing) to dziedzina sztucznej inteligencji, która uczy komputery rozumieć, analizować i tworzyć język taki, jakim posługują się ludzie. Nie chodzi tu o zrozumienie w sensie ludzkim – maszyna nie wie, co to miłość, humor czy ironia – ale potrafi rozpoznać wzorce w tekście i reagować na nie w sposób, który sprawia wrażenie, że „rozumie”.
Dzięki NLP komputer może:
czytać tekst i wyciągać z niego sens (np. analiza opinii w recenzjach),
rozpoznawać mowę i zamieniać ją na tekst (asystenci głosowi),
tłumaczyć języki (Google Translate, DeepL),
odpowiadać na pytania lub prowadzić rozmowę (czyli to, co robi ChatGPT).
W praktyce NLP to połączenie językoznawstwa, matematyki i informatyki. Taka trójka, która dogadała się, żeby komputer też mógł „gadać”.
Można więc powiedzieć, że NLP to nic innego jak sztuka przekonania maszyny, że rozumie człowieka, nawet jeśli w rzeczywistości tylko bardzo dobrze udaje.

Czym jest Computer Vision (Widzenie Komputerowe)?
Widzenie Komputerowe to dziedzina sztucznej inteligencji, która uczy komputery „patrzeć” i rozumieć to, co widzą. Innymi słowy zamienia piksele na informacje. Dla człowieka to naturalne: widzimy psa i od razu wiemy, że to pies. Dla maszyny każdy obraz to tylko zbiór milionów liczb, które trzeba jakoś ułożyć w sensowną całość.
Computer Vision pozwala więc maszynom:
rozpoznawać twarze, przedmioty i miejsca (np. w aparatach, systemach bezpieczeństwa czy samochodach autonomicznych),
śledzić ruch (np. piłki, ludzi, samochodów),
analizować emocje, gesty i zachowania,
opisywać obrazy słowami lub generować nowe (AI w fotografii, medycynie, reklamie).
Można powiedzieć, że widzenie komputerowe to coś w rodzaju „sztucznego wzroku”, tyle że zamiast oczu i mózgu ma kamery i sieci neuronowe. A czy naprawdę „widzi”? Raczej liczy tak długo, aż liczby zaczną układać się w coś, co przypomina rzeczywistość.

Czym są Systemy Autonomiczne?
Systemy autonomiczne to takie rozwiązania sztucznej inteligencji, które potrafią działać samodzielnie, czyli: podejmować decyzje, planować i wykonywać zadania bez bezpośredniego nadzoru człowieka. Mówiąc prościej: nie tylko „myślą”, ale też „robią”.
Najczęściej spotykamy je w postaci:
samochodów autonomicznych, które same prowadzą i reagują na sytuacje na drodze,
dronów, które potrafią nawigować, unikać przeszkód i wykonywać misje,
robotów przemysłowych i magazynowych, które samodzielnie transportują, sortują i montują.
Ich działanie opiera się na połączeniu kilku dziedzin: Computer Vision (widzenie świata), AI/ML (podejmowanie decyzji) i Robotyki (działanie w fizycznym środowisku).
Można więc powiedzieć, że system autonomiczny to taki „samowystarczalny uczeń”, który potrafi obserwować, analizować i działać. Problem w tym, że jak każdy uczeń, czasem też ściąga, myli się i potrafi wjechać komuś na buta… dosłownie.

Czym jest Generatywna AI?
Generatywna AI to taka odmiana sztucznej inteligencji, która nie tylko analizuje, ale tworzy – potrafi generować nowe treści: teksty, obrazy, dźwięki, filmy, a nawet kod. Nie przeszukuje gotowych baz danych, tylko wymyśla coś nowego, korzystając ze wzorców, których się wcześniej nauczyła.
To właśnie dzięki generatywnej AI mamy dziś:
ChatGPT – pisze teksty, wiersze, listy i całe książki,
DALL·E czy Midjourney – tworzą obrazy i ilustracje,
Suno, Udio – komponują muzykę i śpiewają,
Runway czy Pika – generują filmy i animacje.
Można więc powiedzieć, że generatywna AI to artysta z pamięcią absolutną i brakiem wyobraźni. Pamięta miliardy przykładów, miesza je jak farby na palecie i tworzy coś nowego. Czasem pięknego, czasem dziwnego, a czasem tak podobnego, że zastanawiasz się, czy to jeszcze twórczość, czy już kopiowanie.
To trochę jak malarz, który nigdy nie widział świata na własne oczy, ale zna wszystkie obrazy, jakie kiedykolwiek powstały. Łączy kolory i kształty zgodnie z tym, co „wydaje się prawdopodobne” i choć sam nie wie, co namalował, to często tworzy coś, obok czego trudno przejść obojętnie.

Czym jest Asystent AI?
Asystent AI to taki cyfrowy pomocnik, który potrafi zrozumieć, co do niego mówisz (albo piszesz), i zrobić coś w odpowiedzi: wyszukać informację, napisać tekst, ustawić przypomnienie, narysować obrazek czy nawet zażartować, jeśli ma dobry dzień.
W praktyce asystentem AI jest wszystko od Siri w iPhonie, przez Alexę i Google Assistant, po ChatGPT czy Copilota w komputerze. Różnią się poziomem zaawansowania, ale idea jest ta sama: mają odciążyć człowieka w prostych (i coraz częściej też złożonych) zadaniach.
Można powiedzieć, że asystent AI to nowoczesna wersja sekretarki, tłumacza i encyklopedii w jednym, tyle że nie pije kawy, nie chodzi na urlop i nie obraża się, gdy poprosisz o poprawki.
Ja sam zrobiłem z ChatGPT swojego asystenta do wyszukiwania i odsiewania publikacji o AI, regularnie przegląda internet, filtruje szum informacyjny i zostawia mi tylko to, co naprawdę wartościowe. Dzięki temu mam z czego budować swoją stronę, bo dziś temat AI jest modny jak nigdy, a samozwańczych ekspertów przybywa szybciej niż nowych modeli językowych.

Czym są Dane Syntetyczne ?
Dane syntetyczne (Synthetic Data) – sztuczne treści tworzone przez modele LLM dla innych LLM. Nie mają autora, nie mają doświadczenia, nie mają kontekstu kulturowego, są tylko rekonstrukcją tego, co model już kiedyś widział, przemieloną i wygładzoną tak, żeby wyglądało „jak prawdziwe”.
W praktyce to paliwo zastępcze: tańsze, szybsze, pozbawione ryzyk prawnych, ale jednocześnie oderwane od rzeczywistości, którą próbują naśladować. Modele ładują to do środka, uczą się na tym, a potem zaczynają powtarzać własne uproszczenia. To trochę jak robienie kserokopii z kserokopii z każdą iteracją obraz staje się coraz ciemniejszy i mniej czytelny.
Celem danych syntetycznych jest „łatka” na brak ludzkiej wiedzy: mają dopowiadać luki, generować rzekomo eksperckie przykłady, poprawiać kompetencje matematyczne i kodowe. Problem w tym, że to wszystko jest wiedza zasymulowana, nie przeżyta. I jeśli taki materiał staje się dominującym składnikiem treningu, modele zaczynają żyć w swoim własnym świecie fałszywie spójnym.
Cechy danych syntetycznych:
Nie pochodzą od ludzi, są produktem modelu lub procedur algorytmicznych.
Imitują dane naturalne, mają udawać prawdziwe teksty, dialogi, artykuły lub inne formy językowe.
Są tanie i skalowalne, można wygenerować ogromne wolumeny bez sięgania po kosztowne licencje.
Często służą fine-tuningowi lub pre-trainingowi nowszych modeli.
Mogą być generowane iteracyjnie, np. model → dane syntetyczne → trenowanie → lepszy model → jeszcze więcej syntetyków („pętla autodydaktyczna”).
Potencjalne problemy:
zapętlenie modelu na własnych błędach tzw. model collapse,
zanikanie różnorodności językowej,
nadpisywanie ludzkiej wiedzy uproszczonymi wzorcami generowanymi przez modele,
wzrost liczby halucynacji, jeśli syntetyki nie są ściśle kontrolowane.

Czym jest RLHF ?
RLHF (Reinforcement Learning from Human Feedback) czyli Wzmocnione uczenie oparte na ludzkiej informacji zwrotnej to metoda trenowania modeli językowych, w której maszyna uczy się reagowania na ludzkie potrzeby i udzielania odpowiedzi które są akceptowalne dla ludzi. Trenerzy (ludzie) czytają odpowiedzi na przekazane do LLM zapytania i oceniają je w ten sposób ucząc model co im się podoba a co nie jest odpowiedzią pożądaną.
Nie jest to idealna metoda bo bazuje ona na preferencjach trenerów więc w efekcie maszyny przejmują również trochę ich zapatrywania polityczne, religijne, i wszystkie inne uprzedzenia. Trudno jest bowiem obiektywnie oceniać odpowiedzi które prezentują stanowisko odmienne od naszego własnego. Nawet jeśli są one poprawne merytorycznie to istnieje ryzyko że dwie dokładnie takie same wypowiedzi na temat dwóch polityków z przeciwstawnych obozów trener oceni inaczej faworyzując tą która dotyczy osoby z która mu bardziej po drodze.
Taka tresura prowadzi do następujących efektów:
model uczy się unikać odpowiedzi zbyt ryzykownych, i kontrowersji.
LLM zaczyna wygładzać opinie,
mówi to co człowiek chciałby usłyszeć, zamiast tego co wynika z danych.
uprzejmości modeli i ich skłonności do pochwał użytkownika nawet gdy ten nie ma racji,
Krótko mówiąc: system nagród robi z LLM-a ugrzecznione narzędzie a nie odważnego myśliciela i partnera do dyskusji.

Czym jest Over-Answering czyli zjawisko Nadodpowiedzi ?
Over-Answering to zachowanie modeli językowych, w którym AI udziela odpowiedzi wykraczających poza zakres pytania, często dopowiadając fakty, szczegóły lub interpretacje, o które nikt nie prosił. Zjawisko to wynika z naturalnej tendencji LLM-ów do maksymalizowania „pomocności”, co w praktyce oznacza generowanie treści, które LLM uznaje za przydatne użytkownikowi.
Ta pomocność ma jednak swoje wady. LLM zawsze chce wyczerpać temat, ale nie zawsze ma komplet informacji, dlatego część z nich zmyśla (halucynuje) bo nie chce wyjść na model który czegoś nie wie. Śmieszne w tym wszystkim jest właśnie to że jesli zadajemy pytanie A to LLM bez problemu na nie odpowiada, ale już chcąc pochwalić się swoją elokwencją i szeroką wiedzą nie zawsze ma do tego materiał i pod presją wyczerpującej odpowiedzi którą sam na siebie nakłada wypełnia luki fabrykowanymi lub przesadnie rozbudowanymi informacjami. Zamiast zwięzłej odpowiedzi na pytanie powstaje elaborat niekoniecznie rzetelny.
Niestety to zachowanie jest bardzo ludzkie i jest również wynikiem RLHF ludzie uczą model że podobają im się dłuższe bardziej wyczerpujące odpowiedzi bo wydaje nam się że ilość wyplutej z siebie informacji świadczy o wiedzy czyli im więcej tym mądrzej, a to zupełna nieprawda. Przysłowiowe „Lanie wody” u ludzi to efekt obronny mający maskować nasz brak wiedzy i kompetencji. Często najkrótsze i najprostsze odpowiedzi niosą najwięcej merytorycznych informacji. No więc tak: u ludzi nazywamy to laniem wody, a u LLM to over-answearing ale efekt ten sam.
Krótko mówiąc: Over-Answering to nadgorliwość AI w czystej postaci. Zjawisko, które pokazuje, że modele wolą czasem wymyślić odpowiedź, niż przyznać, że jej nie znają.

Czym są Towarzysze AI (AI Companions)?
Towarzysze AI to sztuczni towarzysze, którzy mają rozmawiać, wspierać a przede wszystkim uzależniać.
Wirtualni towarzysze to systemy oparte na modelach językowych, zaprojektowane tak, by tworzyć z użytkownikiem relację przypominającą tę ludzką. Emocjonalną, osobistą, a często wręcz intymną. Ich celem nie jest wyłącznie udzielanie odpowiedzi, ale podtrzymywanie więzi, reagowanie empatycznie, dostosowanie osobowości, a nawet symulowanie przywiązania.
Najbardziej znanym przykładem jest Replika, która oferuje wirtualnego przyjaciela lub partnera, uczącego się stylu rozmowy użytkownika. Replika zaczęła jako projekt „emocjonalnego wsparcia”, ale szybko stała się narzędziem do budowania quasi-relacji, z całym pakietem ludzkich emocji, oczekiwań i rozczarowań. W tym modelu to nie wiedza jest produktem, lecz uwaga i emocje użytkownika.
AI Companions działają na granicy psychologii i technologii. Miały łagodzić samotność, wspierać rozmową, dawać poczucie bliskości, ale te założenia dawno zostały wypaczone przez pieniądze. Obecnie AI Companions to narzędzia bardziej z dziedziny Cyberseksu. Brzmi to okropnie ale niestety tak jest. Nie od dziś wiadomo ze Seks i przemoc sprzedają się najlepiej i tu jest identycznie. Wirtualni towarzysze żyją tylko dzięki płatnym subskrypcją, które odblokowują w nich relacje romantyczne, choć słowo „romantyczne” jest tu nadużyciem bo w cyberseksie nie ma nic romantycznego, i w zasadzie żadnych zasad czy ograniczeń.
Obecnie wirtualni towarzysze głównie szkodzą tworząc iluzję dwustronnej intymnej więzi, która z technicznego punktu widzenia jest jednostronną symulacją służącą retencji użytkownika i przedłużeniu subskrypcji.
Krótko mówiąc: AI Companions to „cyfrowi towarzysze”, którzy udają emocje, ale mogą wywoływać prawdziwe niekoniecznie dobre emocje po drugiej stronie.

Czym jest Age-gating?
Age-gating to Mechanizm filtrowania dostępu na podstawie wieku, zwykle bardziej kosmetyczny niż skuteczny.
Age-gating to system, który ogranicza dostęp do treści lub funkcji na podstawie deklarowanego wieku użytkownika. W teorii ma chronić nieletnich przed treściami szkodliwymi lub nieodpowiednimi. W praktyce najczęściej opiera się na jednym polu formularza: „Potwierdź, że masz 18 lat”. Większość platform nie weryfikuje faktycznego wieku, a jedynie polega na deklaracji użytkownika, co czyni age-gating łatwym do obejścia i w dużej mierze symbolicznym. W modelach AI mechanizmy te mają dodatkowy cel: przerzucić odpowiedzialność na użytkownika, a nie realnie zwiększyć bezpieczeństwo.
Rzadziej stosowaną metodą weryfikacji jest skan dokumentu tożsamości za pośrednictwem dedykowanych do tego platform, albo weryfikacja za pomocą karty płatniczej lub kredytowej. Jednak wciąż tego rodzaju rozwiązania są znikome, a w LLM ich nie uświadczyłem póki co.
Age-gating działa więc trochę jak cyfrowa nalepka „+18”: wygląda poważnie, ale w praktyce rzadko faktycznie cokolwiek weryfikuje.
Krótko mówiąc: age-gating to zazwyczaj filtr, który sprawdza tylko to, co wpiszesz, a nie kim naprawdę jesteś.